Quickly getting started with Deep Reinforcement learning on Atari games

The last few weeks I have been experimenting with deep neural networks for Reinforcement Learning. Reinforcement Learning is a way to learn to apply a sequence of events and has its root in control problems. Recent years it has been combined with deep neural networks to train a neural network on the game state and determine the next best action to take in video games. If you are unfamiliar with the topic of Reinforcement Learning please have a look at the following link which explains it nicely: https://deepsense.ai/what-is-reinforcement-learning-the-complete-guide/
For the sake of brevity I will assume this bit of prior knowledge on this topic. In this blog post I will show how you can set up a reinforcement learning experiment yourself to train an agent to play the decades old Atari 2600 Space Invaders game. While this topic has been explored many times over the last years I found it very hard to get a working example on my computer due to the many Python packages required and the pace at which at which their developments are moving. Furthermore lots of tutorials and walkthroughs available on the web don’t explicitly state the versions of the packages they used.
Setting up a Python environment
For starters I highly recommend installing Anaconda from https://www.anaconda.com for managing your Python environments. Anaconda allows you to run multiple versions of Python in parallel with specific versions of required packages that you can bundle in an environment. Anaconda is available for Linux, Windows and Mac. Regarding OS choice I only have experience with Windows and Linux, from which Linux is better supporter in the community. You will find that you will be able to set up many experiments on Windows just as fine, but I have seen a few cases where Windows was not properly supported by specific packages, especially when installing Python packages which required some form of C/C++ compilation. Of course there are Windows compilers available but it seems that the general community is running these types of programs on Linux, which never gave me issues. If you are completely unfamiliar Linux with it I recommend Linux Mint which even can be run from a USB stick. The Python version I recommend using is Python 3.7. I know this is a 4-year old release but more recent releases gave me various issues and 3.7 was stable throughout without compatibility issues. For setting up a reinforcement learning environment the following other packages are required:
- OpenAI Gym: a sandbox environment in which you can train an intelligent agent. The OpenAI Gym Retro project allows to use retro gaming emulators as a sandbox. Amongst the supported emulators are Atari 2600, Nintendo (NES), Sega MegaDrive (Genesis) and the Super Nintendo (SNES)
- A library for training deep neural networks such as Tensorflow or PyTorch
- A reinforcement learning framework like Keras-RL2, Ray rllib, Stable Baselines, etc. In this example I will be using Keras-RL2.
The OpenAI retro project does a fantastic job of exposing various open source emulators for use with a reinforcement learning agent, however the project is still in a pre-1.0 release phase where new versions tend to break previous behavior (for instance the often-used env.render() function to show the console output is now deprecated in version 0.21.0). This type of API-breaking changes tend to break the upper reinforcement learning framework as well, so it is important to keep track of the versions that are meant to work together. I will be using the following versions of required packages:
- python==3.7.11
- tensorflow==2.3.1
- gym==0.18.0
- keras_rl2==1.0.4
- atari_py==0.2.9
- autorom==0.4.2
Just type pip install tensorflow==2.3.1 to install the required version and repeat for all packages.
Now you need to import the Atari ROM files into the emulator. First download the ROMs by typing autorom on the command line and accepting the license. The output will show in which directory the ROMs have been stored. Change into this directory and import the ROMs into the emulator with the following command:
python -m atari_py.import_roms .
This will move the roms into the folder of the emulator. At this point your environment is set up to start your first training your first reinforcement learning agent.
Training an agent
I will be training an agent to learn to play Space Invaders for this example. Globally there are two approaches to learning Atari games:
- Learn from the game state as it is represented on screen. The Atari 2600 boasts a resolution of 160x192 pixels on 3 color channels making total of 92160 input variables.
- Learning the game state from its internal representation from the Atari 2600 RAM. As the RAM size is only 128 bytes this makes an equal number of input variables.
I will present solutions for both approaches.
Training on video output
For training on the video output I will show a solution as presented by Nicholas Renotte in the following Youtube video: https://www.youtube.com/watch?v=hCeJeq8U0lo
The idea is to train an convolutional neural network to process the video output which narrows down using various filter layers to two fully connected layers and in the end to a vector of size 6 indicating one of 6 controller actions which are valid for playing Space Invaders (NOOP, FIRE, RIGHT, LEFT, RIGHTFIRE, LEFTFIRE). Note that the controller has more actions which are not used by Space Invaders.
Start your program with importing the dependencies:
import gym
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Convolution2D
from tensorflow.keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.memory import SequentialMemory
from rl.policy import LinearAnnealedPolicy, EpsGreedyQPolicy
from rl.callbacks import ModelIntervalCheckpoint
WEIGHTS_FILENAME = f'spaceinv_weights.h5f'
CHECKPOINT_WEIGHTS_FILENAME = 'spaceinv_weights_{step}.h5f'
The function which builds the convolutional neural network using Keras looks as follows:
def build_model(height, width, channels, actions):
model = Sequential()
model.add(Convolution2D(32, (8,8), strides=(4,4), activation='relu', input_shape=(3,height, width, channels)))
model.add(Convolution2D(64, (4,4), strides=(2,2), activation='relu'))
model.add(Convolution2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(actions, activation='linear'))
return model
Now we will define a function for creating the DQN Agent which trains the model using Keras-RL2. Note that it is set to a “Epsilon Greedy Policy” decreasing from 1 to 0.1 every step during the training process, so in the first step Epsilon = 1 and at the last step it is 0.1. An Epsilon of 0.1 means that the probability of the agent selecting a random action not given by the neural network is 10%, while in the beginning this probability is much larger. This means the agent is more adventurous in the beginning and will forcibly try new activities in order to learn better.
The window length of 3 means that apart from the current step it also inputs the previous 2 steps into the neural net. This is meant to train the effect of a sequence of activities.
def build_agent(model, actions):
policy = LinearAnnealedPolicy(EpsGreedyQPolicy(), attr='eps', value_max=1., value_min=.1, value_test=.2, nb_steps=10000)
memory = SequentialMemory(limit=1000, window_length=3)
dqn = DQNAgent(model=model, memory=memory, policy=policy,
enable_dueling_network=True, dueling_type='avg',
nb_actions=actions, nb_steps_warmup=1000
)
return dqn
The last bit of code creates the Gym environment and kicks off the training process. Note that the learning rate is a bit larger than in Nicholas’ code to improve training performance a bit.
env = gym.make('SpaceInvaders-v0')
height, width, channels = env.observation_space.shape
actions = env.action_space.n
print(env.unwrapped.get_action_meanings())
model = build_model(height, width, channels, actions)
model.summary()
callbacks = [ModelIntervalCheckpoint(CHECKPOINT_WEIGHTS_FILENAME, interval=5000)]
dqn = build_agent(model, actions)
dqn.compile(Adam(lr=0.00025))
dqn.fit(env, callbacks=callbacks, nb_steps=10000, visualize=False, verbose=2)
dqn.save_weights(WEIGHTS_FILENAME, overwrite=True)
You will notice that when running the program training progresses quite slowly, obviously depending on your hardware. The reason for this can be found in the Keras summary of the network as shown below, the total number of trainable parameter exceeds 34 million!
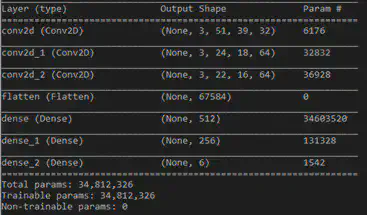
Nicholas recommends the network to train for 10 million steps to see a well-playing agent which was a bit too much in my situation. Other approached on the web create a greyscale image of each frame and rescale the image to 84x84 in order to decrease the number of trainable parameters. This may definitely help and not loose to much information, however this is outside of this approach.
Training on console RAM
An interesting alternative for training on the screen output is looking into the 128-byte RAM of the Atari 2600. This should be representative of some form of the Space Invaders grid layout with its various aliens, however it is unclear which byte exactly represents what. The amount of memory is so low however it can just be input into a regular densely-connected feed forward neural network and see what that delivers.
Again import the packages and set some constants:
import gym
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Convolution2D
from tensorflow.keras.optimizers import Adam
from rl.agents import DQNAgent
from rl.memory import SequentialMemory
from rl.policy import LinearAnnealedPolicy, EpsGreedyQPolicy
from rl.callbacks import ModelIntervalCheckpoint
NUM_STEPS = 10000000
WINDOW_LENGTH = 3
WEIGHTS_FILENAME = f'spaceinv_ram_weights.h5f'
CHECKPOINT_WEIGHTS_FILENAME = 'spaceinv_ram_weights_{step}.h5f'
Now define a function that creates the feed-forward neural network using Keras. Note that the input shape is a tensor of size (3, 128), indicating the 128-byte RAM size and the 3-step window length, meaning that apart from the current step the memory contents of the previous 2 steps are also input into the neural network. This tensor is flattened into an array of size 384 which serves as the neural network input.
def build_model(ram_size, actions):
model = Sequential()
model.add(Flatten(input_shape=(3,ram_size)))
model.add(Dense(512, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(actions, activation='linear'))
return model
The function for the Keras-RL2 agent is the same:
def build_agent(model, actions):
policy = LinearAnnealedPolicy(EpsGreedyQPolicy(), attr='eps', value_max=1., value_min=.1, value_test=.2, nb_steps=NUM_STEPS)
memory = SequentialMemory(limit=1000, window_length=WINDOW_LENGTH)
dqn = DQNAgent(model=model, memory=memory, policy=policy,
enable_dueling_network=True, dueling_type='avg',
nb_actions=actions, nb_steps_warmup=1000
)
return dqn
The remainder of the code kicks off the training process. Note the callback to the ModelIntervalCheckpoint class which creates a checkpoint every 50000 iterations.
env = gym.make('SpaceInvaders-ram-v0')
ram_size = env.observation_space.shape
actions = env.action_space.n
model = build_model(ram_size, actions)
model.summary()
callbacks = [ModelIntervalCheckpoint(CHECKPOINT_WEIGHTS_FILENAME, interval=50000)]
dqn = build_agent(model, actions)
dqn.compile(Adam(lr=0.00025))
dqn.fit(env, callbacks=callbacks, nb_steps=NUM_STEPS, visualize=False, verbose=2)
dqn.save_weights(WEIGHTS_FILENAME, overwrite=True)
Now the network architecture printed by Keras looks much more sensible:
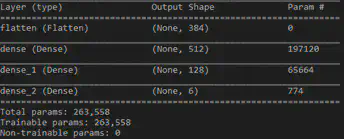
The performance of the training is much better than on the previous example and is able to finish 10 million steps in several hours of training.
Wrapup
I have shown you two approaches of getting started with training your own agent for playing the Atari 2600 game of Space Invaders using a deep reinforcement learning technique using Keras-RL2, both by using the console video output and its internal game state from RAM.
At this point I have found more suitable approaches for beginners which allow you to get started even more quickly, so please stay tuned for a new blog post where I will describe new ways for getting into reinforcement learning.
Dirk Kemper
data scientist - AI enthousiast - analytics consultant
I am an AI and machine learning enthousiast with 20+ years of experience in various fields of IT such as software development, consulting and data science. On this blog I will be writing about professional and personal projects in the areas of machine learning, data science and AI.