
Querying Complex Database Schemas With GPT and Langchain
Summary
- GPT-based models have inherent problems such as correctly aggregating figures in tabular structures and getting access to corporate data in database system
- I will show an approach how to connect GPT to your custom database schema using the Langchain Python package, making use of its SQLDatabaseChain. This allows text-based queries to be executed on the custom database schema.
- Using this approach GPT shows impressive results in its ability to formulate complex SQL queries to the database, including queries containing 3 table joins and is able to retrieve the correct data from the database.
Introduction
The last few blog posts I have written were about extending the use of GPT-based models for tasks as question answering from tabular data and answering questions from documents.
In this post I will extend upon both of those ideas to examine what the capabilities are of these large language models for navigating more complex custom database schemas. This will touch upon two main drawbacks of the GPT-based models:
- GPT cannot calculate: as I have shown in my blog post on question answering from tabular data, GPT is prone to miscalculate the simplest of additions. To circumvent this, I have shown that by moving the data into a SQL-supported database and using GPT to generate the SQL instead, this is a good combination of the right tool for the right job (e.g. GPT for SQL generation and the database for aggregating numbers).
- GPT does not have knowledge about your custom dataset: data living in either your knowledge platform like SharePoint or in a corporate database like an ERP-system, warehouse management system or point of sale solution. This either requires finetuning your model on your custom dataset or using a library like LlamaIndex to include the domain knowledge with your prompt.
Today I will combine these two observations by investigating if GPT can be used for answering text-based questions about data in a SQL-based database, using a custom schema and a custom dataset that GPT has no knowledge of.
Data and database schema
The data I have used is posted to Github at the following link: https://github.com/kemperd/langchain-sqlchain/tree/main/data
Each of the CSV-files needs to be store in its own table. I have used DBeaver (https://dbeaver.io) for this purpose which offers a nice mass import feature to bulk load all CSVs into their own table at once.
The CSV files represent a retail dataset with some point of sale transactions with references across three different dimensions:
- Product dimension containing a reference to a product group
- Location dimension containing city, state and location (grouping of states)
- Store dimension containing store, store brand and a chain
This is also depicted in the following entity relationship diagram:
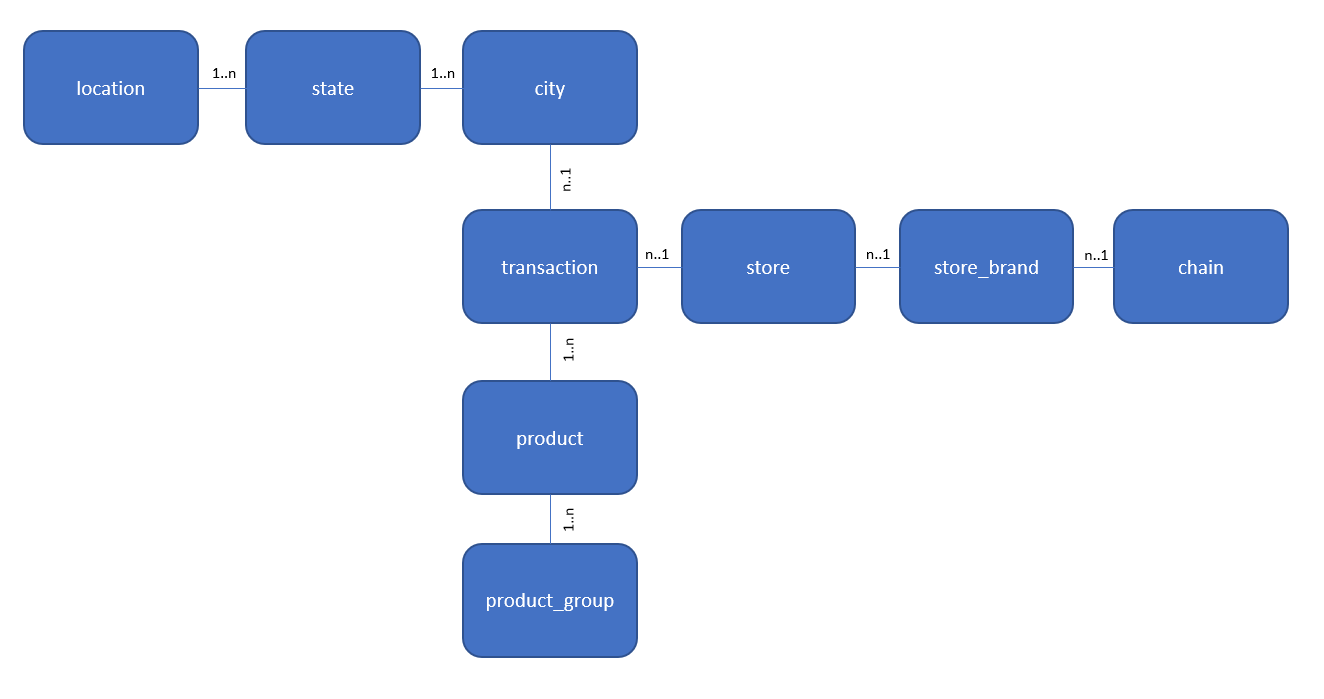
Each of the entities is represented by its own table in the database. To give an example of their usage, if you want to group all sales figures by chain this would require joining the transactions, stores, store_brands and chains tables to navigate from the chain to the stores present in that chain.
Although this schema is a bit simpler than any actual database schema from a large enterprise system, it is clear that this is not a trivial database and requires some bit more intelligence than simply joining a helper table to a table with transactions. Let’s see how well GPT performs on this dataset!
Langchain
For interacting with the database and sending the results to GPT I will be using the Langchain Python package (https://python.langchain.com).
The main idea behind Langchain is that interactions with GPT are based on multiple steps where the intermediate results require some logic or processing for the next step to start. This makes it a very flexible package, able to perform tasks like question answering on custom documents, similar to LlamaIndex which I blogged about earlier, which is in fact based on Langchain.
For this task I will be using a chain type called SQLDatabaseChain, which main task is to provide GPT with information from custom databases.
The SQLDatabaseChain performs the following steps when answering a query which could be answered from the database:
- Open a connection to the target database using SQLAlchemy
- Inspect which tables exist in target database schema
- Identify which table or joins of tables may be used for answering the query
- Look up the schema of the table and the first 3 example records to get an idea of its contents
- Construct a SQL query to answer the original text-based query
- Execute the query and return results
The workbook and instructions to get started on your own hardware is located at: https://github.com/kemperd/langchain-sqlchain. Note that the SQLAlchemy connection string is based on an SAP HANA-database, please update this to your own database accordingly.
Example questions
I will be using the following set of example questions. For each question I have denoted the aspect which is challenging towards retrieving the information.
| # | Query | # tables | Challenge |
|---|---|---|---|
| 1 | Sum up the total revenue | 1 | Aggregation over transactions table |
| 2 | Sum up the total revenue in March 2014 | 1 | Aggregation over transactions table with filter on date |
| 3 | Aggregate the revenue by city, give the top 10 descending | 1 | Aggregation over transaction table, group by city |
| 4 | Sum up the total revenue for all Finn Depot stores | 1 | Aggregation over transaction table, substring selection on store name |
| 5 | Aggregate the revenue by product. Do not return the Product ID but use the descriptions instead. Also return the aggregated revenue for the product | 2 | Needs to join products table to transactions table to get product descriptions |
| 6 | Aggregate the revenue by product group. Do not return the Product Group ID but use the product group descriptions instead. Also return the aggregated revenue for the product group | 3 | Needs join of 3 tables: transactions, products and product_groups |
| 7 | Aggregate the revenue by state, give the top 10 descending | 3 | Needs join of 3 tables: transactions with states with city-table in between |
| 8 | Aggregate the number of sold items for all store brands with the string “mart” in the store brand name. Give the top 10 descending, also include the aggregated quantities. | 3 | Need join of 3 tables: transactions, stores, store_brands, requires substring selection on store brand name |
Code
You can view the required code in the notebook at https://github.com/kemperd/langchain-sqlchain/blob/main/langchain-sqlchain.ipynb. For using the SQLDatabaseChain the following packages are required:
from langchain.sql_database import SQLDatabase
from langchain.chat_models import ChatOpenAI
from langchain import SQLDatabaseChain
from urllib.parse import quote
from sqlalchemy import create_engine, select, Table, MetaData, Column, String
from dotenv import load_dotenv
import os
I will be using python-dotenv package for loading the connection parameters from a local .env file:
load_dotenv()
Now connecting to the database is done using a SQLAlchemy connection string. Note that this is based on an SAP HANA-database, please update this to your own database accordingly.
username = str(os.getenv('DB_USER'))
passwd = str(os.getenv('DB_PASS'))
hostname = str(os.getenv('DB_HOST'))
port = str(os.getenv('DB_PORT'))
db = SQLDatabase.from_uri("hana://{}:{}@{}:{}".format(username, quote(passwd), hostname, port))
At this point, we are able to create a SQLDatabaseChain as below. Note the use of gpt-3.5-turbo as a model which I will get into later on.
db_chain = SQLDatabaseChain(llm=ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo'), database=db, verbose=True)
Now running a query is just a matter of the following line:
db_chain.run("Sum up the total revenue")
Results
Q1: Sum up the total revenue
> Entering new SQLDatabaseChain chain...
Sum up the total revenue
SQLQuery:SELECT SUM(sales_revenue) FROM transactions
SQLResult: [(Decimal('2051658.33'),)]
Answer:The total revenue is $2,051,658.33.
> Finished chain.
Analysis: The query and answer are correct.
Q2: Sum up the total revenue in March 2014
> Entering new SQLDatabaseChain chain...
Sum up the total revenue in March 2014
SQLQuery:SELECT SUM(sales_revenue) FROM transactions WHERE "Date" BETWEEN '2014-03-01' AND '2014-03-31'
SQLResult: [(Decimal('50250.39'),)]
Answer:The total revenue in March 2014 was $50,250.39.
> Finished chain.
Analysis: The query and answer are correct.
Q3: Aggregate the revenue by city, give the top 10 descending
> Entering new SQLDatabaseChain chain...
Aggregate the revenue by city, give the top 10 descending
SQLQuery:SELECT city, SUM(sales_revenue) AS revenue
FROM transactions
GROUP BY city
ORDER BY revenue DESC
LIMIT 10
SQLResult: [('NEW ORLEANS', Decimal('54676.84')), ('MEMPHIS', Decimal('36251.51')), ('SAN DIEGO', Decimal('32109.34')), ('SCHAUMBURG', Decimal('25327.49')), ('LITTLE ROCK', Decimal('23224.58')), ('MINNEAPOLIS', Decimal('22285.38')), ('LOS ANGELES', Decimal('21154.46')), ('PHOENIX', Decimal('20957.72')), ('PORTLAND', Decimal('17717.21')), ('JACKSON', Decimal('17581.97'))]
Answer:The top 10 cities by revenue are: NEW ORLEANS, MEMPHIS, SAN DIEGO, SCHAUMBURG, LITTLE ROCK, MINNEAPOLIS, LOS ANGELES, PHOENIX, PORTLAND, and JACKSON.
> Finished chain.
Analysis: the aggregated revenue per city is correctly queried in the SQL and also seems to be returned from the results. However the final answer from the GPT model is only a sorted list of cities and does not include the revenue figures as I would expect. We probably need to be more clear about this in the prompt.
Q4: Sum up the total revenue for all Finn Depot stores
> Entering new SQLDatabaseChain chain...
Sum up the total revenue for all Finn Depot stores
SQLQuery:SELECT SUM(sales_revenue) FROM transactions WHERE store LIKE '%Finn Depot%'
SQLResult: [(Decimal('65285.74'),)]
Answer:The total revenue for all Finn Depot stores is $65,285.74.
> Finished chain.
Analysis: The query and answer are correct.
Q5: Aggregate the revenue by product. Do not return the Product ID but use the descriptions instead. Also return the aggregated revenue for the product
> Entering new SQLDatabaseChain chain...
Aggregate the revenue by product. Do not return the Product ID but use the descriptions instead. Also return the aggregated revenue for the product
SQLQuery:SELECT p.description, SUM(t.sales_revenue) AS revenue
FROM transactions t
JOIN products p ON t.product_id = p.product
GROUP BY p.description, t.product_id
SQLResult: [('Rain Jacket', Decimal('6875.65')), ('Gloves', Decimal('424299.72')), ('Boots', Decimal('453573.81')), ('Beef Jerky', Decimal('18425.93')), ('Water', Decimal('13024.14')), ('Bucket', Decimal('359492.33')), ('Nails', Decimal('7561.1')), ('Mop', Decimal('714269.83')), ('Hammer', Decimal('35042.56')), ('Canteen', Decimal('8698.91')), ('Tarp', Decimal('10394.35'))]
Answer:The revenue aggregated by product is:
- Rain Jacket: $6,875.65
- Gloves: $424,299.72
- Boots: $453,573.81
- Beef Jerky: $18,425.93
- Water: $13,024.14
- Bucket: $359,492.33
- Nails: $7,561.10
- Mop: $714,269.83
- Hammer: $35,042.56
- Canteen: $8,698.91
- Tarp: $10,394.35
> Finished chain.
Analysis: here we can see the results of the model joining two tables to get the product descriptions. Note that the prompt explicitly stated to return the descriptions, if this would not have been given the model resorts to returning the product IDs which do not require an extra join. Also note that in this case the aggregated figures are returned next to the product descriptions as explicitly asked for.
Q6: Aggregate the revenue by product group. Do not return the Product Group ID but use the product group descriptions instead. Also return the aggregated revenue for the product group
> Entering new SQLDatabaseChain chain...
Aggregate the revenue by product group. Do not return the Product Group ID but use the product group descriptions instead. Also return the aggregated revenue for the product group
SQLQuery:SELECT pg.description AS "Product Group", SUM(t.sales_revenue) AS "Total Revenue"
FROM transactions t
JOIN products p ON t.product_id = p.product
JOIN product_groups pg ON p.product_group = pg.product_group
GROUP BY pg.description
SQLResult: [('Apparel', Decimal('884749.18')), ('Camping', Decimal('19093.26')), ('Grocery', Decimal('31450.07')), ('Household', Decimal('1116365.82'))]
Answer:The total revenue aggregated by product group is:
- Apparel: $884,749.18
- Camping: $19,093.26
- Grocery: $31,450.07
- Household: $1,116,365.82
> Finished chain.
Analysis: this answer required joining 3 tables to get the correct answers which is handled well by the model.
Q7: Aggregate the revenue by state, give the top 10 descending
> Entering new SQLDatabaseChain chain...
Aggregate the revenue by state, give the top 10 descending
SQLQuery:SELECT states.description, SUM(transactions.sales_revenue) AS revenue
FROM transactions
JOIN cities ON transactions.city_id = cities.city
JOIN states ON cities.state = states.state
GROUP BY states.description
ORDER BY revenue DESC
LIMIT 10
SQLResult: [('California', Decimal('256911.3')), ('Illinois', Decimal('153531.71')), ('Arkansas', Decimal('121844.14')), ('Massachusetts', Decimal('111027.32')), ('Louisiana', Decimal('98948.63')), ('Connecticut', Decimal('93239.07')), ('Mississippi', Decimal('91824.31')), ('Michigan', Decimal('72786.22')), ('Texas', Decimal('72510.87')), ('Tennessee', Decimal('61129.04'))]
Answer:The top 10 states by revenue are: California, Illinois, Arkansas, Massachusetts, Louisiana, Connecticut, Mississippi, Michigan, Texas, and Tennessee.
> Finished chain.
Analysis: once more a correct join of 3 tables, but no aggregated figures returned. This aligns with previous queries as this was not explicitly requested in the prompt.
Q8: Aggregate the number of sold items for all store brands with the string “mart” in the store brand name. Give the top 10 descending, also include the aggregated quantities.
> Entering new SQLDatabaseChain chain...
Aggregate the number of sold items for all store brands with the string “mart” in the store brand name. Give the top 10 descending
SQLQuery:SELECT sb.store_brand, SUM(t.quantity_sold) AS total_sold
FROM store_brands sb
JOIN stores s ON sb.store_brand = s.store_brand
JOIN transactions t ON s.store = t.store
WHERE sb.store_brand LIKE '%mart%'
GROUP BY sb.store_brand
ORDER BY total_sold DESC
LIMIT 10
SQLResult: []
Answer:There are no results for this query, as there are no store brands with the string "mart" in their name.
> Finished chain.
Analysis: this is the first and only query from the example which does not come close to being correct. Note that the main table in the query’s FROM-clause store_brands instead of transactions. Furthermore the actual store brand name is a column called description in the store_brands table which is nowhere to be seen in this query. Because of the incorrect base table and join the query returns nothing.
Token usage
A drawback of this solution may be the large number of tokens sent across to GPT. Please take into account that by default Langchain uses the text-davinci-003 model, which is not a bad model at all but quite expensive for token-heavy solutions like this. Note that in my Jupyter notebook I have switched to gpt-3.5-turbo, which is 10 times cheaper than the default model, adding only a few cents to your API usage limit when running the notebook.
Wrapup
This blog post has demonstrated how to pair the impressive code generation capabilities of GPT to an actual database with a custom database schema and custom data, in order to have GPT answer queries directly from the database. While 1 out of 8 queries has a quite obvious problem, the remaining 7 are handled well, including queries requiring joins over 3 tables. This shows that we have once more found a topic where language models are taking over activities from knowledge workers.
GPT-3 GPT-4 Langchain HANA Tabular data RAG