Timelapse data exploration of NYC taxi rides
Nowadays in 2021 the NYC archive has grown substantially and allows you to download data from 2009 up until the present year. It now not only contains yellow taxi trips but also green taxi and for hire vehicles (e.g. Lyft and Uber). It suffices to state that this is a massive amount of data and still poses a true big data case up until this date. Even with today’s technology loading, storing and analyzing the full 12 years dataset may still prove to be challenging.
Please have a look at the following link for the full downloadable set: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
I did a few experiments and analyses on this dataset over the last years that I will be sharing over the next months as way to document progress and wrap up the project folders. In this blog post I will show you a way to create an animated timelapse overview of the trip pickups on a NYC map.
The end result will look somewhat like the following:
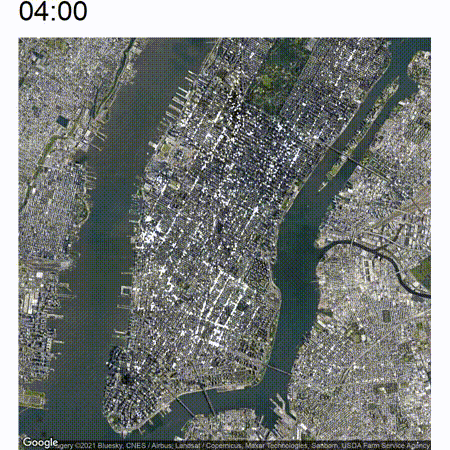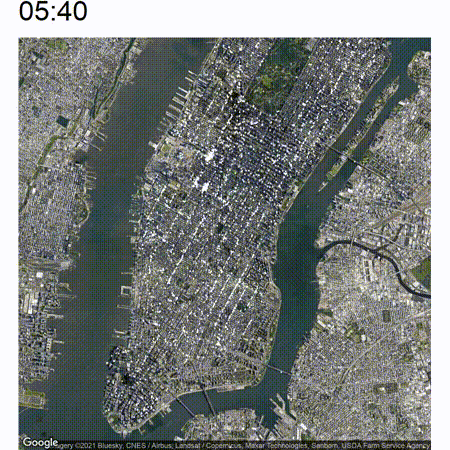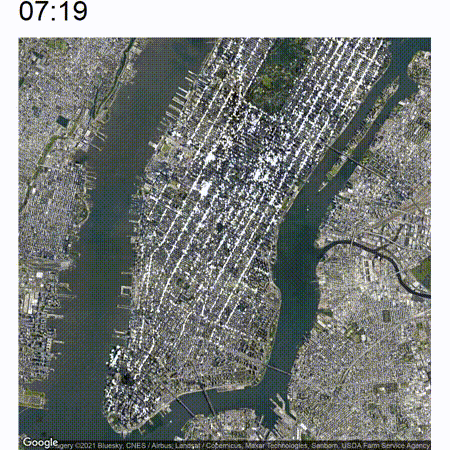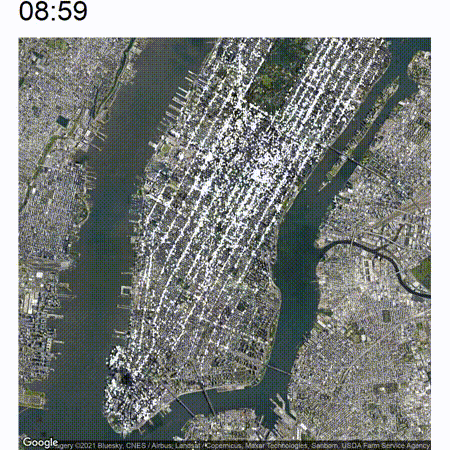
High-level approach
In this example I will be using the ‘yellow_tripdata_2014-01.csv’ file which obviously contains all yellow cab trips for January 2014. This file alone contains about 13.7 million trips.
The high-level approach is as follows:
- Load the dataset into a HANA database
- Connect R to HANA to extract the trip information
- Plot the trip files onto individual maps for each minute of the day
- Stitch together the minute images into a video
Loading the data into HANA
For this example, I will be using the aforementioned SAP HANA Express database for storing the data. You can switch this with any other SQL compatible database if you wish, currently I prefer this product as professionally I am leaning towards HANA.
To try HANA Express out yourself refer to the following link for downloading it: https://www.sap.com/products/hana/express-trial.html
For these examples it is sufficient to download the ‘Database only’ product which is smaller in size and requires less hardware overhead than the ‘server + applications’ package which includes XSA. I recommend to reserve at least 16 GB for the database and another 8-16 GB for the scripts, so make sure to run it on a computer with 24 to 32 GB of memory.
Follow the included instructions to install and start the HANA database. After starting up create a user for yourself and use the below SQL to create a table. This is going to store information on each trip contained in the monthly file. The database structure consists of a staging table (to prevent the loading process crashing from data type errors when loading the large file) and a final table. As you can see the staging table just assigns VARCHAR(50) to all fields whereas the final table assigns the correct datatypes.
CREATE COLUMN TABLE "YELLOW_TRIPDATA_STAGING" ("vendor_id" NVARCHAR(50),
"pickup_datetime" NVARCHAR(50),
"dropoff_datetime" NVARCHAR(50),
"passenger_count" NVARCHAR(50),
"trip_distance" NVARCHAR(50),
"pickup_longitude" NVARCHAR(50),
"pickup_latitude" NVARCHAR(50),
"rate_code" NVARCHAR(50),
"store_and_fwd_flag" NVARCHAR(50),
"dropoff_longitude" NVARCHAR(50),
"dropoff_latitude" NVARCHAR(50),
"payment_type" NVARCHAR(50),
"fare_amount" NVARCHAR(50),
"surcharge" NVARCHAR(50),
"mta_tax" NVARCHAR(50),
"tip_amount" NVARCHAR(50),
"tolls_amount" NVARCHAR(50),
"total_amount" NVARCHAR(50)
);
Now create another table which contains the data with the final data types:
CREATE COLUMN TABLE "YELLOW_TRIPDATA" ("vendor_id" NVARCHAR(3),
"pickup_datetime" TIMESTAMP,
"dropoff_datetime" TIMESTAMP,
"passenger_count" TINYINT,
"trip_distance" DECIMAL(10,2),
"pickup_longitude" DECIMAL(11,8),
"pickup_latitude" DECIMAL(10,8),
"rate_code" TINYINT,
"store_and_fwd_flag" NVARCHAR(1),
"dropoff_longitude" DECIMAL(11,8),
"dropoff_latitude" DECIMAL(10,8),
"payment_type" NVARCHAR(3),
"fare_amount" DECIMAL(7,2),
"surcharge" DECIMAL(7,2),
"mta_tax" DECIMAL(7,2),
"tip_amount" DECIMAL(7,2),
"tolls_amount" DECIMAL(7,2),
"total_amount" DECIMAL(7,2)
);
Use Eclipse / HANA Studio to import one of the downloaded CSVs from the NYC website into the table by using File -> Import -> SAP HANA Content -> Data from local file. Make sure to check the Header Rows checkbox and optionally fill in a start and end line to limit the amount of rows. This process can take quite a bit of time (about 1.5 hours on my fairly slow machine) so please be patient.
Now fill the final table from the staging table using the following statement:
insert into YELLOW_TRIPDATA("vendor_id", "pickup_datetime", "dropoff_datetime", "passenger_count",
"trip_distance", "pickup_longitude", "pickup_latitude", "rate_code", "store_and_fwd_flag",
"dropoff_longitude", "dropoff_latitude", "payment_type", "fare_amount", "surcharge", "mta_tax",
"tip_amount", "tolls_amount", "total_amount")
SELECT "vendor_id", TO_TIMESTAMP("pickup_datetime",'YYYY-MM-DD HH24:MI:SS'), TO_TIMESTAMP("dropoff_datetime",'YYYY-MM-DD HH24:MI:SS'), "passenger_count",
"trip_distance", TO_DECIMAL("pickup_longitude"), TO_DECIMAL("pickup_latitude"), "rate_code", "store_and_fwd_flag",
CASE WHEN LENGTH("dropoff_longitude") > 0 THEN TO_DECIMAL("dropoff_longitude") ELSE NULL END,
CASE WHEN LENGTH("dropoff_latitude") > 0 THEN TO_DECIMAL("dropoff_latitude") ELSE NULL END,
"payment_type", "fare_amount", "surcharge", "mta_tax",
"tip_amount", "tolls_amount", "total_amount"
FROM YELLOW_TRIPDATA_STAGING
This all happens in memory so only takes a minute. To see if the import worked get some quick descriptive statistics on the dataset:
select count(*), min("pickup_datetime"), max("pickup_datetime"), sum("tip_amount"), sum("total_amount") from yellow_tripdata;
Afterwards you can clear the staging table using the below statement to free up space:
TRUNCATE TABLE "YELLOW_TRIPDATA_STAGING";
Connecting to HANA using R
I will now show a way to present the trips graphically using R. I recommend to install RStudio from https://www.rstudio.com and to download the latest version of R from https://www.r-project.org/.
We will use the HANA ODBC connection to connect to the database. This is included in the “HANA Clients” package you can install through the HANA Express download manager you have used to download HANA Express. If you didn’t install this package back then just re-open the download manager to install it now. Follow through the installation process to install the HANA ODBC driver on your computer.
Now click your Start menu and type ‘ODBC’. Open the control panel for 64-bit ODBC data sources. Now add a new System DSN called ‘hxehost’ and type in the connectivity details for your system and database users.
Start up RStudio and use Tools -> Install packages to install ‘RODBC’, ‘GGally’ and ‘ggmap’. First do a quick check on the connectivity by using the below script. Update your password where necessary.
library("RODBC");
ch<-odbcConnect("hxehost",uid="ML_USER",pwd="Password");
sqlQuery(ch, "SELECT COUNT(*) FROM YELLOW_TRIPDATA")
This should give you the 13.7 million rows from the file.
Setting up Google Maps usage
In this example I will be using Google Maps’ satellite view as a graphical mapping layer. This is a bit more difficult than it used to be, however you can work around this by using the “Stamen” mapping layer instead. I like the visual effect of the darker satellite view though. As of recent years you’ll need an API key to connect to Google Maps for which you’ll need to link it to your credit card for optional billing. According to Google you’ll be able to make about 28.000 API calls before your free tier expires, which is more than enough.
For more information type the following into RStudio to get the corresponding ggmap documentation:
?register_google
You can register yourself at https://cloud.google.com/maps-platform/. If you get asked to add additional protection to your API key you could use API-based protection and make sure to select the “Maps Static API” or skip additional protection altogether. If you don’t want to use Google Maps, please check the ?get_stamenmap help page.
Plotting the trips on a map
For plotting the trips on a map view I’ll be using packages GGally and ggmap which extract images off Google Maps and allow them to be used as a layer in ggplot2 for you to plot further data on. You should have installed these in the previous step.
Please have a look at the full program first, I will explain the steps later.
library(GGally)
library(RODBC)
library(ggplot2)
library(ggmap)
library(dplyr)
library(stringr)
library(foreach)
library(doParallel)
register_google("YOUR_GOOGLE_MAPS_API_CLOUD_KEY")
ch <- odbcConnect("hxehost",uid="ML_USER",pwd="Password");
# Extract all trips from database
trips <- sqlQuery(ch, 'SELECT lpad(extract(hour from "pickup_datetime"),2,\'0\') || \':\' || lpad(extract(minute from "pickup_datetime"),2,\'0\') as "pickup_time", "pickup_longitude", "pickup_latitude" FROM YELLOW_TRIPDATA')
df_trips <- data.frame(trips)
map_manh <- get_googlemap(center = c(lon = -73.98631218292147, lat = 40.739080438366145), maptype="satellite", zoom = 13)
map_penn <- get_googlemap(center = c(lon = -73.98527737647392, lat = 40.75181735482003), maptype="satellite", zoom = 15)
# Extract all minutes in which there were trips
times <- sqlQuery(ch, paste('select lpad(extract(hour from "pickup_datetime"),2,\'0\') || \':\' || lpad(extract(minute from "pickup_datetime"),2,\'0\') as time ',
'from yellow_tripdata ',
'group by lpad(extract(hour from "pickup_datetime"),2,\'0\') || \':\' || lpad(extract(minute from "pickup_datetime"),2,\'0\') ',
'order by lpad(extract(hour from "pickup_datetime"),2,\'0\') || \':\' || lpad(extract(minute from "pickup_datetime"),2,\'0\')' )
)
genmaps <- function () {
i <- 0
gen_map_path <- 'c:/gen_maps'
for(cur_time in times$TIME) {
df.min <- filter(df_trips, pickup_time == cur_time)
# Manhattan full
ggmap(map_manh, extent="device") + geom_point(color="white", alpha=0.7, size=0.05, aes(x = pickup_longitude, y = pickup_latitude), data = df.min) + ggtitle(cur_time)
filename <- paste0(gen_map_path, '/manh_', str_pad(i, 6, pad="0"), '.jpg')
ggsave(filename, device="jpg", width=900, height=900, units='px')
# Closeup Pennsylvania Station
ggmap(map_penn, extent="device") + geom_point(color="white", alpha=0.7, size=0.2, aes(x = pickup_longitude, y = pickup_latitude), data = df.min) + ggtitle(cur_time)
filename <- paste0(gen_map_path, '/penn_', str_pad(i, 6, pad="0"), '.jpg')
ggsave(filename, device="jpg", width=900, height=900, units='px')
i <- i+1
}
}
genmaps()
The above program will perform the following steps:
- Extract all relevant trip information from the database
- Extract two maps we will be analyzing from Google Maps: a full overview of Manhattan and a closeup around Pennsylvania Station we will analyze later
- Define a function genmaps() which extracts all valid minutes from the database and aggregates the number of trips on that minute. In practice due to the massive size of the dataset every minute will have at least one trip recorded.
- The genmaps() function will loop through the valid minutes and create a .jpg file for each minute on which the pickups are plotted. This will be done for both maps.
Execute the code without the last line by stepping through it with CTRL+Enter and make sure it runs without problems. Before running the final function for creating the maps make sure you have created a folder called ‘gen_maps’ on your C-drive. Modify the folder name if needed.
To generate all images just execute genmaps(). This will take quite a bit of time as each image file is processed and saved to disk individually in a for loop which is definitely not a strong suit of R. This workload should be easily parallelizable as the end result is a bunch of individual files, but I gave up on getting it to work as I couldn’t get that to work quickly and doesn’t need to run often.
After running through the program, you have ended up with a folder c:\gen_maps which contains files manh_000001.jpg through manh_001439.jpg and similarly penn_000001 through penn_001439.jpg. Open a few of the images in an image editor to see the result.
Stitching the images together
The last step of stitching the images together is just a matter of processing them through a tool to create an MPEG file. I will be using ffmpeg for this task inside an Ubuntu Windows Subsystem for Linux host. For more details on setting this up yourself if you are running Windows please visit https://ubuntu.com/wsl.
Use the following command for installing ffmpeg:
sudo apt-get install ffmpeg
Just answer yes to also install the large amount of dependencies.
Now navigate to your c:/gen_maps directory (or otherwise) by changing into /mnt/c/gen_maps and using the following command:
/usr/bin/ffmpeg -y -r 30 -i manh_\%6d.JPG -vcodec libx265 tl_manh.mp4
This will create a tl_manh.mp4 file with your end result.
Additionally to create an animated GIF (like I used for this site) convert the video file once more:
/usr/bin/ffmpeg -y -ss 8 -t 10 -i tl_manh.mp4 -vf "scale=600:-1" tl_manh.gif
This will create a 10-second GIF starting from second 8, scaled down to a 600 width image with auto-scaled height.
Some observations
Now the nice thing about this animated view is that you are able to view an increase or decrease in traffic pretty easily which will not be immediately apparent if you just analyze still pictures. Take a look at the below image which is a cutout of the timelapse between around 05:00 and 07:00. In the middle of the image there are some white clusters which start to grow at around 06:00 at the west end of Bryant Park.
The below image shows a closeup of this development. You can spot the green Bryant Park somewhat in the middle of the image.
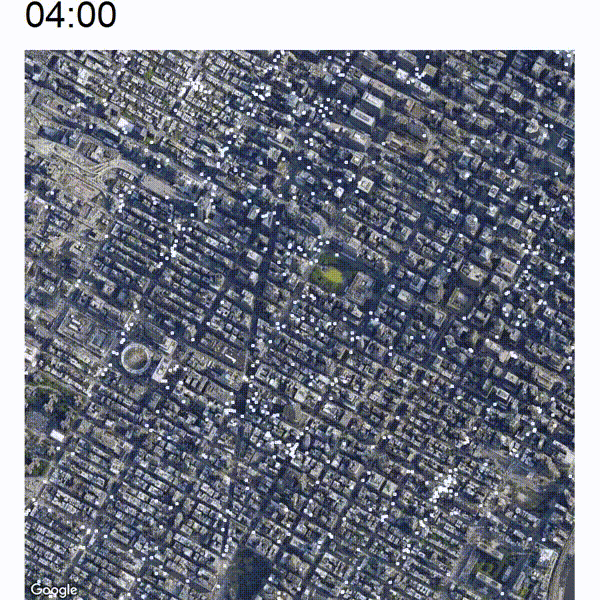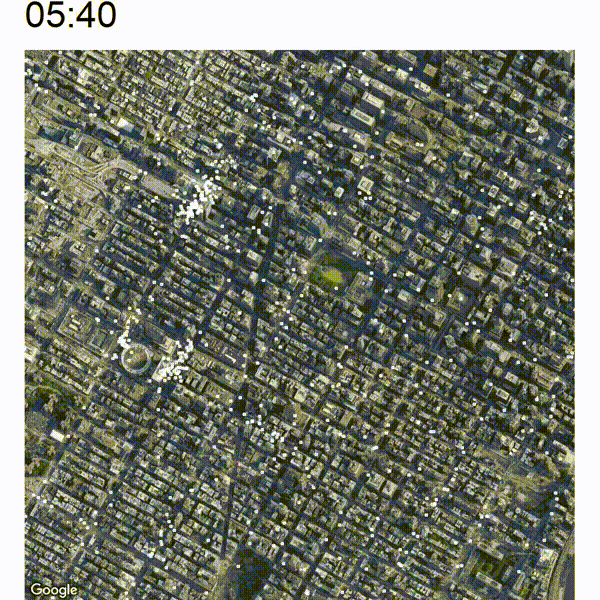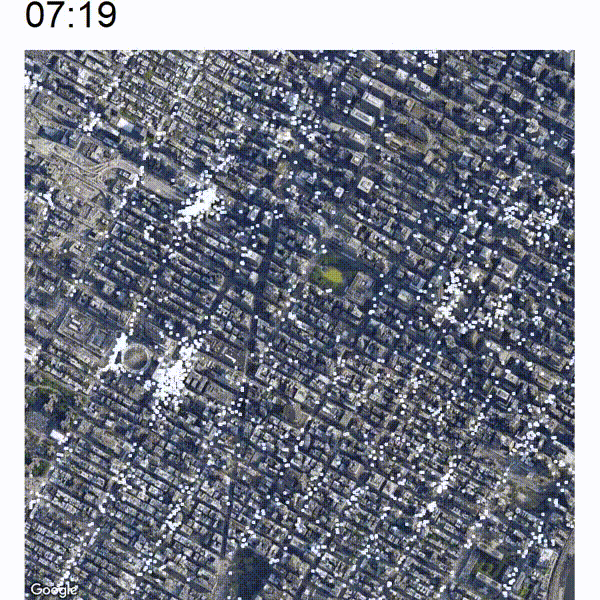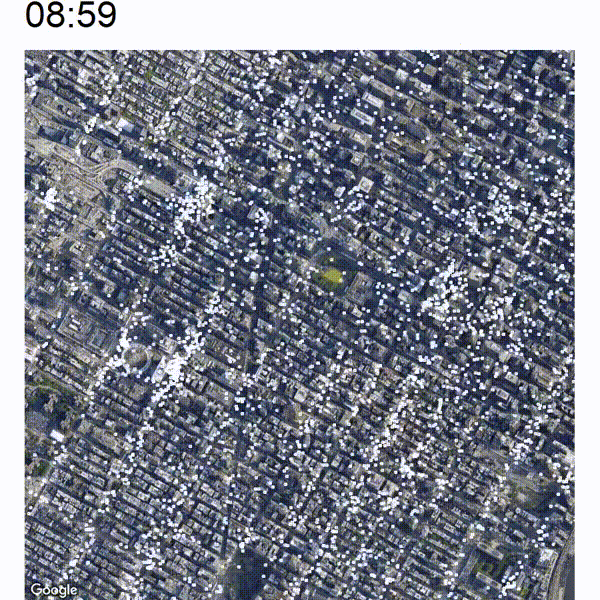
It seems that the clusters are originating at the east and west side of Pennsylvania Station (large circular building at the bottom-left) and also at the 42 St Port Authority Bus Terminal (top-left cluster). There is also a bit of heightened activity at the east side of Bryant Park which is the Grand Central Terminal. It looks like commuter trains and buses arrive early in the morning at those terminals whose passengers are traveling along to their final destination by yellow cab.
Dirk Kemper
NYC Taxi rides R Timelapse Exploratory Data Analysis