
Running a Large Language Model on Your Own Hardware
Introduction
Last November ChatGPT has held its first anniversary, after having reached a user base of 180 million active users, making this the fastest adopted technology with an internet user base ever.
Now we are a year in, I’d like to explore how the open-source world has caught up with ChatGPT’s success. What is the current state of affairs when comparing open source LLMs to the closed source and proprietary models from OpenAI and others? Is open-source technology able to match or surpass the technology brought by OpenAI in 2022?
To understand why these developments are important you should consider a few benefits of publicly available open source LLMs:
-
Cost savings: the LLMs provided by OpenAI and consequently Microsoft all have per-request billing associated to them, which can become an expensive exercise when many users in an enterprise are using the models in parallel. As the open-source alternatives are intended to run locally on lower-cost hardware requiring smaller or even consumer-grade GPUs, their costs will be much lower.
-
Privacy: as the proprietary models are run on remote cloud infrastructure, they need to be queried through APIs. It is known that the OpenAI API but also ChatGPT stores all model interactions for future training purposes, which exposes a data leak risk to businesses. The case of Samsung employees accidentally sharing confidential information with ChatGPT is one of the more prominent examples of this issue https://mashable.com/article/samsung-chatgpt-leak-details. An LLM running on private infrastructure will not be susceptible to these problems.
-
Access to model weights: the model weights make up the actual substance of the model and are used to initialize the neural network performing the text generation. Having access to these weights means it is possible to use the released model as a basis for further training or finetuning on your specific dataset. For hosted models this will only be possible when the vendor has an API available for this and will possibly bill you accordingly. An open-source alternative will be much easier and cheaper to tailor to your specific data.
Comparing open source models to ChatGPT
The paper from Chen et al. from Nanyang University at https://arxiv.org/abs/2311.16989 provides a great status update of the open source LLM world. It uses a few benchmarks such as MT-Bench and AlpacaEval to provide a ranking of some popular recent open-source models and stacks them up against their closed-source rivals from OpenAI.
I will focus on the “General Capabilities” benchmarks of this paper, which provides the following results. Please note the table is the property of the paper’s authors.
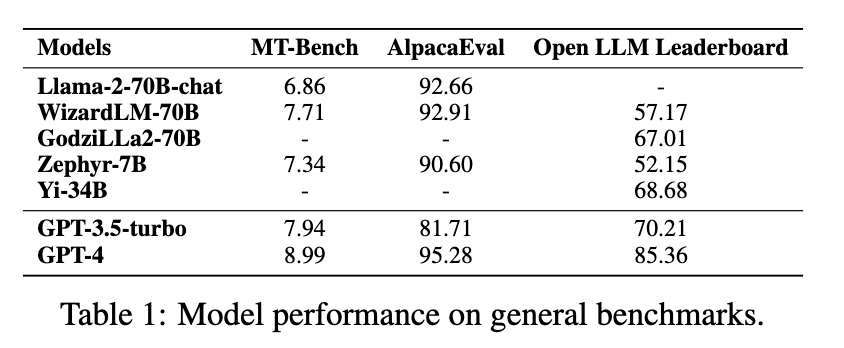
Note that the free version of ChatGPT is using GPT-3.5-turbo as its main text generation model. You’ll notice that GPT-3.5-turbo is surpassed in the AlpacaEval-benchmark by three open-source models: Meta’s Llama-2, WizardLM and Zephyr-7B, which means that in a year’s time we are now able to download and run an open-source alternative comparable to ChatGPT!
Running an LLM on your own hardware
Now I will demonstrate a way to run one of the mentioned open-source alternatives on your own hardware. As the Zephyr-7B model is the smallest in terms of GPU memory requirements, I will select this and on your own hardware. It ran fine with my 12 GB GPU, although you may get away with an 8 GB GPU as well.
These instructions will also be valid when deploying the model on a cloud-based instance, so a relatively cheap AWS p2.large instance with 12 GB of GPU memory should also do the trick.
I will show how to use the text-generation-webui project located at https://github.com/oobabooga/text-generation-webui. The aim of this project is to be the “Automatic1111 of text generation”, which means in practice that it bundles a nice-working UI comparable to ChatGPT with some user-friendly model downloading loading functionality. To get started, create a new Python environment with Anaconda:
conda create env -n text-generation python=3.11
conda activate text-generation
Now install CUDA when using an NVIDIA GPU. For AMD you’ll need ROCm, but as I don’t own one that will be outside the scope of this tutorial.
conda install -y -c "nvidia/label/cuda-12.1.0" cuda-runtime
Now install PyTorch:
pip install torch torchvision torchaudio
Clone the text-generation-webui project from Github:
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
Install the remaining requirements for the project:
pip install -r requirements.txt
This concludes installing the project and dependencies. You should now be able to start the GUI using:
python server.py
Open the link as displayed on the screen (default http://127.0.0.1:7860)
To install the Zephyr model, the most straightforward way is to use the GUI itself. First navigate to the Model-tab which looks as follows:
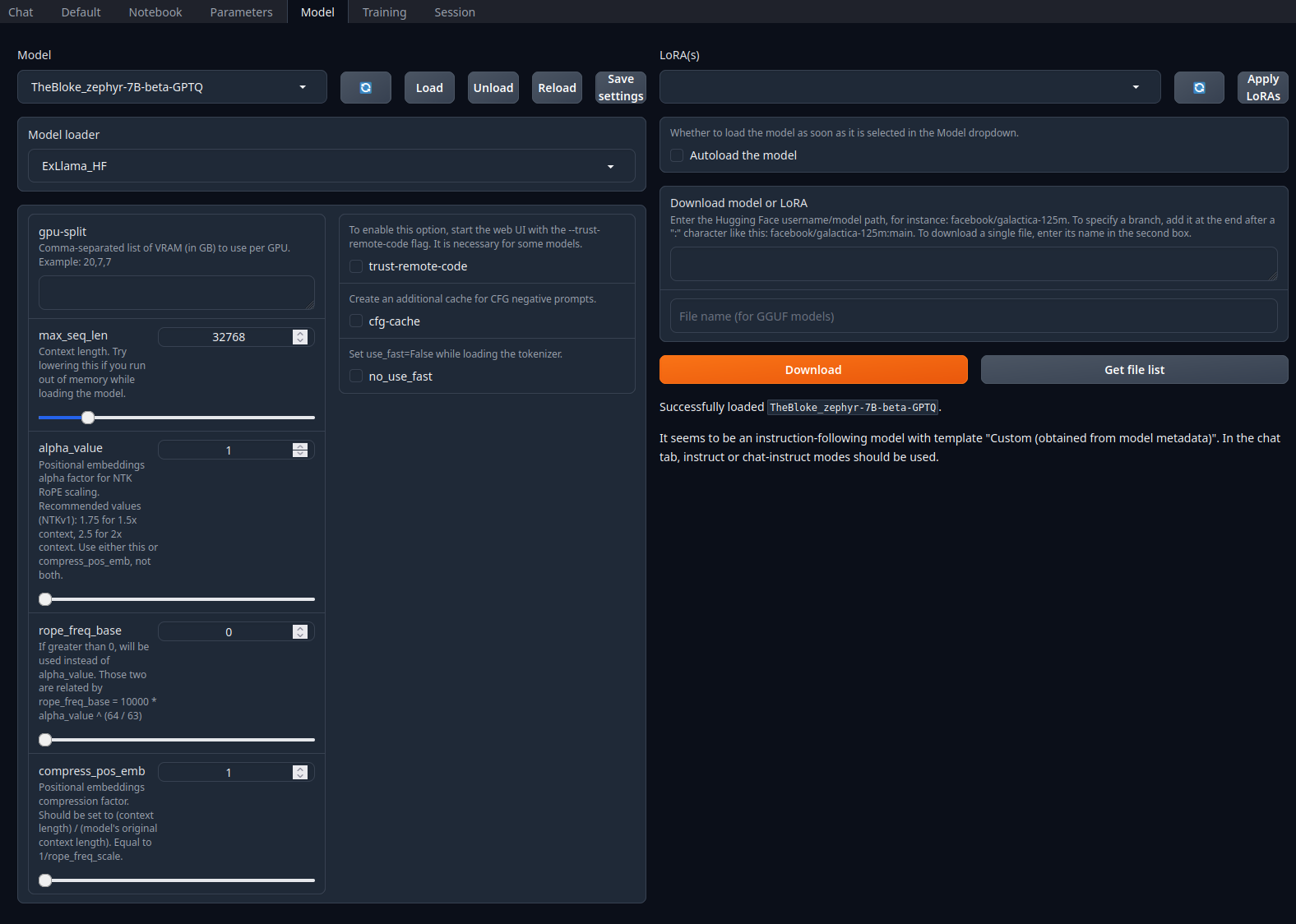
- At “Download model or LoRA”, enter:
TheBloke/zephyr-7B-beta-GPTQ - Click Download
- Click the Refresh-icon at the top-left close to Model
- Now select the
Zephyr-7B-beta-GPTQmodel - Click Load
- Navigate to the Chat-tab and scroll down to the bottom
- Select
chat-instructat section “Mode”
This will load the model into the GPUs memory, allowing you to start chatting with the LLM. A screenshot of the main interface looks as follows:
Alternative models
An alternative to Zephyr-7B is its parent model Mistral-7B. You can view a list of available Mistral models at the following link: https://huggingface.co/mistralai. Note that Mistral delivers both a model optimized for instruction following and a foundational model which you can view as a compressed version of the body of text it had been trained on. They are both very capable and by using the text-generation-webui it will be very easy to experiment with them all and compare their indented usage. You may also notice that Zephyr has a lot more guardrails built-in to prevent it from engaging in certain conversations where Mistral has less of that.
These alternative models can be installed by using the above steps and using a string like mistralai/Mistral-7B-Instruct-v0.2, just as it is located on the Huggingface hub.
The Mistral models tend to require more GPU memory, so when running into memory limitations the text-generation-webui offers you the option to quantize the models to 8 or even 4 bits, allowing you to still run from your GPU, sacrifing a small amount of output quality. Just look for the 8-bit or 4-bit checkboxes on the model load screen.
Wrapup
The open-source community has really caught up with OpenAI in terms of user experience and output quality, running on only a fraction of the hardware that was required a year ago for ChatGPT. This may seem like a small deal but remember that you are now in control of all parts of the infrastructure, also gaining access to the model weights. Retraining these weights on your own body of text will now be in reach of anyone.
When comparing the quality of Zephyr-7B’s anwers to ChatGPT using a standard benchmark like AlpacaEval, it is now shown that it is now possible to run your own LLM which matches or surpasses ChatGPT in quality right your own hardware.
Dirk Kemper
Zephyr-7B