Master Data Attribute Recommendation using SAP AI Core and T5 Transformers
Background
Errors in the master data system will usually reveal themselves in business intelligence applications aggregating large volumes of transactions into master data attributes, which may lead to significant reporting errors when these are poorly maintained.
To alleviate the process of correctly creating master data items in systems like S4/HANA I will demonstrate an AI model which proposes various master data attributes based on the entered product description.
Model
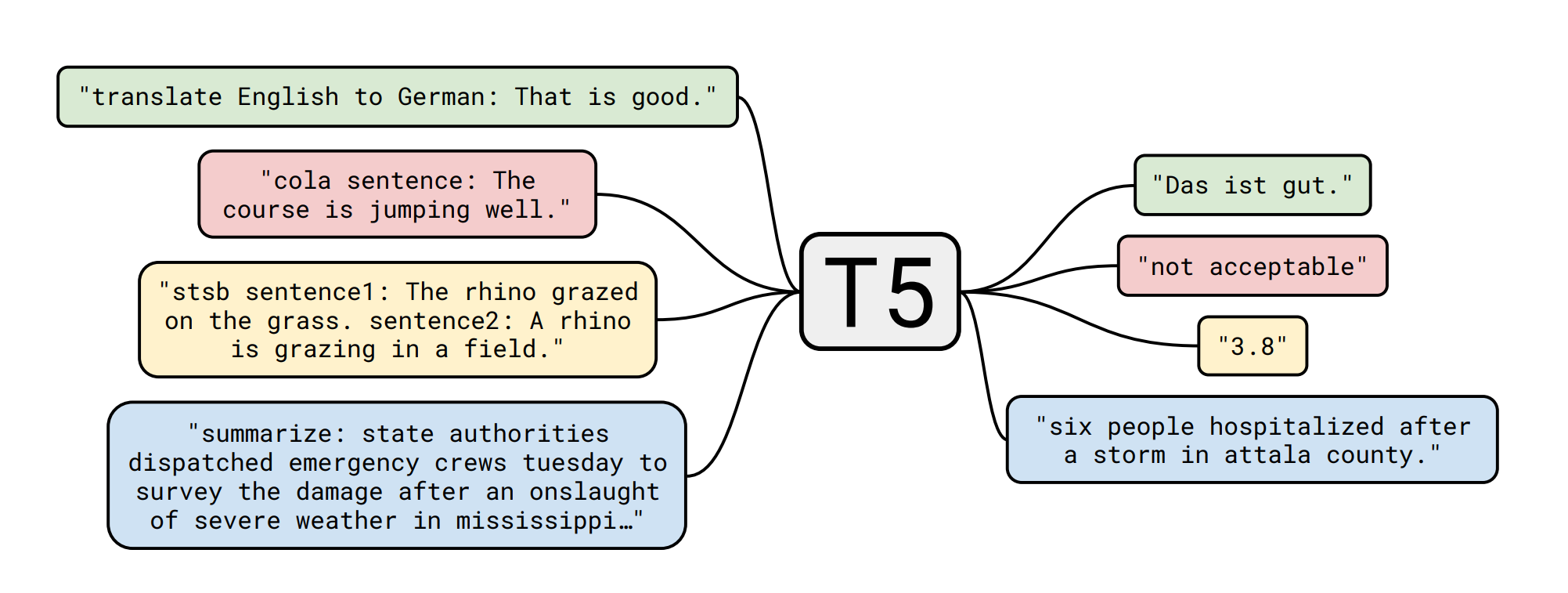
This work has been inspired by the paper Attribute Value Generation from Product Title using Language Models by Roy, Goyal and Pandey1. In their work they demonstrated good performance using the T5 Transformer language model, which stands for Text-To-Text Transfer Transformer and has initially been proposed by a team from Google Research.
Transformer models are a specific architectural type of neural networks meant for language processing and text generation. In this case we will train a T5 model to convert an input string like the following into a recommended attribute:
recommend brand name: Original New Arrival 2018 Adidas GK UP Men’s T-shirts short sleeve Sportswear
This asks the T5 model to extract the brand name (Adidas) from the descriptive product string. For this demo I will train a model which is able to recommend a product’s brand and material (e.g. cotton, steel, carbon, etc.). The transformer will (hence the name) transform the large product description string into a mostly single-word description, indicating for instance it’s brand. The dataset used for these examples is a product dataset from Alibaba to which you can find a link in the paper.
The T5 model is just one of the many available transformer neural network architectures available today. For training the T5 model I will use Python together with the Huggingface Transformers library which is built on top of PyTorch, a library facilitating deep learning development. Huggingface allows for easily setting up the required neural network architecture and also contains a large library of pre-trained neural networks. There are 5 pre-trained T5 networks available, ranging from 60 million (t5.small) to 11 billion parameters. The larger networks may perform better on larger bodies of texts but obviously take more compute resources to retrain on your specific problem and are also larger to download. For this example I will be using the t5.small which already gave acceptable performance on the relatively small string contained in the dataset.
System architecture
I decided to try and deploy the model to SAP AI Core to which I had temporary access. The architecture of this solution is fairly complicated and requires a fair amount of prior understanding of what needs to be set up. It will get easier once you get over the initial learning curve.
You should regard SAP AI Core as a GPU-enabled Docker backend to which you can push your container image and have it run there. As it is based on Docker you have full flexibility over what programming language and libraries you will be using. As I will be using the Transformers library together with PyTorch I selected one of the official pre-built PyTorch Docker images from the PyTorch team, available at https://hub.docker.com/r/pytorch/pytorch/tags.
To get a picture of the overall architecture of SAP AI Core please refer to the following blog post: https://blogs.sap.com/2022/06/13/introduction-of-the-end-to-end-ml-ops-with-sap-ai-core/
This will give you an overview of the high-level components involved and the workflow required to set up model training and a serving workflow in SAP AI Core. I will give my own take on the activities you need to perform in the next section.
Development and deployment workflow
As is the case with any machine learning task the project consists of a train and inference (or apply) phase.
The workflow for setting up a training session using SAP AI Core is as follows:
- Create an AWS S3 bucket and upload your training data
- Create a second S3 bucket where the model resulting from your training session is stored
- Create a Docker image containing your training program. This needs to bundle all required dependencies and should be GPU-enabled. For this project I selected pytorch/pytorch:1.11.0-cuda11.3-cudnn8-runtime which bundles PyTorch 1.11 together with the CUDA libraries required for GPU training.
- Push the Docker image to Docker Hub
- Create a GitHub repository where you will upload the training workflow files
- Create a training workflow file. SAP AI Core’s workflow engine is based on Argo Workflows which combines all the above ingredients: it downloads the Docker image from Docker Hub and downloads the S3 contents to make it available to the training program. After training it moves the resulting model to the destination bucket.
- Upload the training workflow file to the GitHub
Now you will need to instruct SAP AI Core to take all these ingredients and have them work together. There are access tokens to be configured for each of the systems to interact, for more details on this and a step-by-step guide please see the following tutorial: https://developers.sap.com/tutorials/ai-core-tensorflow-byod.html
After having trained your model SAP AI Core will the program writes the resulting model to the S3 bucket you configured earlier. This model serves as an input for a new inference program which requires the following steps:
- Create a Docker image containing your inference program, also based on the same PyTorch Docker image given earlier. This program should listen on a port for HTTP POST requests to which it can act and emit its outputs. In this example this is done using Flask. The application receives an input string in the form of “recommend brand name:
” and outputs an according brand, allowing for straightforward integration into external applications. - Push the Docker image to Docker Hub
- Create the inference workflow file and upload it to the GitHub repository created earlier.
After performing these steps SAP AI Core needs to be instructed to Deploy the inferencing container. This will start up the inference program and listens on the configured port for inferencing requests.
Codebase
All of the code required for the train and inference containers is located on https://github.com/kemperd/attribute-recommendation. To get this to work I recommend to follow the SAP AI Tutorial scenario at https://developers.sap.com/tutorials/ai-core-tensorflow-byod.html and take the code from my GitHub repo as an input for the train and inference docker containers.
Note: all of the code can be ran without SAP AI Core as well!
Just use Python 3.8 and use pip install -r requirements.txt in the code/train and code/infer directories first. Then just use python train.py or python infer.py for training or inference. If the program complains about an environment variable (e.g. NUM_GPUS) not set, make sure to set it first (using SET NUM_GPUS=0 on Windows or export NUM_GPUS=0 on Linux).
Training the T5 model
For training the T5 model I will be using the Huggingface transformers library using the t5-small pretrained network. This network will be retrained on the text corpus containing the product descriptions and their attributes. Retraining an already trained neural network is a fairly common task in other machine learning fields like computer vision and is also referred to as transfer learning.
Please find an excerpt of the dataset below which consists of 3 columns indicating the product name, attribute name and attribute value. The exact attributes available for each product are varying, although the Brand Name is usually available.

The T5 transformer only takes two input variables: a source string and a target string. Furthermore each string you feed to the transformer also need to be prefixed with an action, which in this case I have chosen to be recommend <attribute>, e.g. recommend brand name and recommend material. The input data is therefore translated using Pandas to records resembling the following:
recommend brand name: APG STO0045 Camping Stove Portable Cooking Equipment Welding BBQ Butane Hiking Camping Gas Burners Gas Adapter Torch Lighter
This allows for training a single model which is able to perform all attribute recommendation tasks, which learns which attribute to recommend by checking the action prefix. Although this example only uses two attributes it should be straightforward to extend it with more attributes.
All code for the training setup can be found on my GitHub repo. Note that there are a few parameters tuned by me:
source_max_token_length = 64– this indicates the maximum length of the input descriptiontarget_max_token_length = 8- this indicates the maximum length of the recommended attribute. Both source and target token length have been optimized for this dataset and can be optionally increased at the cost of extended training timepretrained t5 model = t5-small, which has about 60 million parameters. This gave a good combination of fast training performance and good model predictionsmax_epochs = 50– the maximum numbers of one forward and one backward pass through the network, in practice this number is usually not reached in this datasetpatience = 5– the number of epochs where no improvement has been detected before stopping the training
Training of this dataset on SAP AI Core using the infer.s resource plan takes about 15 minutes.
Validating the T5 model results
The T5 transformer model has been trained on product_train_test.csv which contains both train and test examples required for the neural network to train on. I will now validate the results on a hold-out set called product_validation.csv which has not yet been seen by the model. Both CSV files are present in the GitHub repository.
Paste the following code into a Jupyter notebook cell and execute it to check the inference results:
endpoint = f"{deployment.deployment_url}/v1/models/attribute-recommendation-model:predict"
print(endpoint)
predict_data = { 'source_text': 'recommend brand name: Original New Arrival Authentic Nike Air Jordan 5 Retro Low 'Alternate 90' Men's Basketball Shoes Sport Sneakers 819171-001' }
headers = {
"Authorization": ai_api_lm.rest_client.get_token(),
'ai-resource-group': resource_group,
"Content-Type": "application/json"}
response = requests.post(endpoint, headers=headers, params=predict_data)
print('Inference result:', response.json())
Which results in:
https://api.ai.prod.us-east-1.aws.ml.hana.ondemand.com/v2/inference/deployments/dfffe69b13e31c0f/v1/models/attribute-recommendation-model:predict
Inference result: ['Nike']
This means the model has correctly inferred the Nike brand name from the product description. Below you can find a table containing the above example including a few others with their brand names the model inferred from the descriptions:
| Input text | Result |
|---|---|
| recommend brand name: Original New Arrival Authentic Nike Air Jordan 5 Retro Low ‘Alternate 90’ Men’s Basketball Shoes Sport Sneakers 819171-001 | Nike |
| recommend brand name: Original New Arrival 2018 PUMA Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear | PUMA |
| recommend brand name: ONITSUKA TIGER Men’s Shoes MEXICO 66 Women Shoes White gold Sneakers Rubber sole Hard-Wearing Couples Badminton Shoes D507L-0152 | ONUTSIKA TIGER |
| recommend brand name: Adidas New Arrival 2017 Original WV STFRD JKT Men’s jacket Hooded Sportswear BQ6456 | Adidas |
Now remember the model has been trained to recommend both brand names and materials. To start the material recommendation you need to change the prefix to “recommend material:”, which gives the following results:
| Input text | Result |
|---|---|
| recommend material: Free Knight 20L Nylon Outdoor Bags Digital Jungle Camouflage Hunting Hiking Camping Military Tactical Backpack Army Bag | Nylon |
| recommend material: 2017 NOEBY 3section Fishing Rod 3.35m H/XH Carbon FUJI ALCONITE Guides Canna Da Fibra Vara De Pesca Carb Peche Fish Pole | Carbon |
| recommend material: Mens Run Jogging Cotton Shorts Outdoor Sports Parkour Gym Fitness Calf-Length Crossfit Sweatpants Man 2018 New Brand short pants | Cotton |
| recommend material: Journey Wish Women’s Spring Jacket Softshell Fleece Windbreaker Outdoor Sport Coat Hiking Camping Skiing Waterproof Jacket | Fleece |
As you can see the model is performing very well on these examples. Note that all of these have been taken from the hold-out dataset and the model has not been trained on any of them!
Now let’s do some variance on the PUMA brand recommendation example from above. The original example is displayed once more in the top row. I will try out some variances of the positioning of the brand name, capitalization and also changing the brand by a fictional other name.
| Input text | Result |
|---|---|
| recommend brand name: Original New Arrival 2018 PUMA Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear | PUMA |
| recommend brand name: PUMA Original New Arrival 2018 Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear | PUMA |
| recommend brand name: Original New Arrival 2018 Puma Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear | Puma |
| recommend brand name: Original New Arrival 2018 Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear by PUMA | PUMA |
| recommend brand name: Original New Arrival 2018 CHEETAH Evostripe Core FZ Hoody Men’s jacket Hooded Sportswear | CHEETAH |
Clearly the model is robust against positioning and capitalization of the brand name. It also has a correct sense of where the brand name is in the sentence if you replace it with another name. This indicates the model is not wired for searching a fixed string like “PUMA”.
Wrap-up
In this blog post I have shown a method for training an attribute recommendation model based on the T5 transformer neural network. I have used SAP AI Core as a backend for model training and serving the inferencing workflow.
The T5 model appeared to be a very good fit for an attribute recommendation task and worked well the small set of examples I have demonstrated. Performing transfer learning on the smallest pretrained T5 model with only 60 million parameters was sufficient for the model to perform in this attribute recommendation scenario. This also suggests that T5 is intended for much more complex tasks like text summarization or headline suggestion on large bodies of texts, especially when combined with the larger pretrained networks.
Although complex with a steep learning curve, SAP AI Core is a capable environment for training these types of models and hosting the inference workflow.
An obvious improvement to the current set up would be to extend the number of recommendable attributes and to train this on a different and larger dataset.
-
Roy, Goyal, Pandey, Attribute Value Generation from Product Title using Language Models, https://aclanthology.org/2021.ecnlp-1.2.pdf ↩
Dirk Kemper
Deep learning Stable Diffusion